MongoDB MapReduce学习笔记
语法:
db.runCommand(
{ mapreduce : 字符串,集合名,
map : 函数,见下文
reduce : 函数,见下文
[, output : 字符串,统计结果保存的集合。]
[, query : 文档,会在发往map函数前,先用指定条件过滤文档]
[, sort : 文档,会在发往map函数前,先给文档排序]
[, limit : 整数,发往map函数的文档数量上限]
[, keeptemp: 布尔值,链接关闭时临时结果集合是否保存]
[, finalize : 函数,将reduce的结果送给这个函数,做最后的处理]
[, scope : 文档,js代码中要用到的变量]
[, jsMode : 布尔值,是否减少执行过程中BSON和JS的转换,默认true] //注:false时 BSON-->JS-->map-->BSON-->JS-->reduce-->BSON,可处理非常大的mapreduce,
//true时BSON-->js-->map-->reduce-->BSON
[, verbose : 布尔值,是否产生更加详细的服务器日志,默认true]
}
);
测试数据:
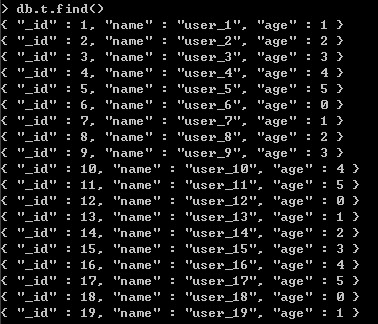
第一步是写映射(Map)函数,可以简单的理解成分组吧~
var m=function(){
emit(this.age,this.name);
}
emit的第一个参数是key,就是分组的依据,这是自然是age了,后一个是value,可以是要统计的数据,下面会说明,value可以是JSON对象。
这样m就会把送过来的数据根据key分组了,可以想象成如下结构:
第一组
{key:0,values: ["name_6","name_12","name_18"]
第二组
{key:1,values: ["name_1","name_7","name_13","name_19"]
......
组中的key其实就是age的值了,values是个数组,数组内的成员都有相同的age!!。
第二步就是简化了,编写reduce函数
var r=function(key,values){
var ret={age:key,names:values};
return ret;
}
reduce函数会处理每一个分组,参数也正好是我们想像分组里的key和values。
这里reduce函数只是简单的把key和values包装了一下,因为不用怎么处理就是我们想要的结果了,然后返回一个对象。对象结构正好和我们想象的相符!:
{age:对应的age,names:[名字1,名字2..]}
最后,还可以编写finalize函数对reduce的返回值做最后处理:
var f=function(key,rval){
if(key==0){
rval.msg="a new life,baby!";
}
return rval
}
这里的key还是上面的key,也就是还是age,rval是reduce的返回值,所以rval的一个实例如:{age:0,names:["name_6","name_12","name_18"]},
这里判断 key 是不是 0 ,如果是而在 rval 对象上加 msg 属性,显然也可以判断 rval.age==0,因为 key 和 rval.age 是相等的嘛!!
这里其他的选项就不说了,一看就知道。
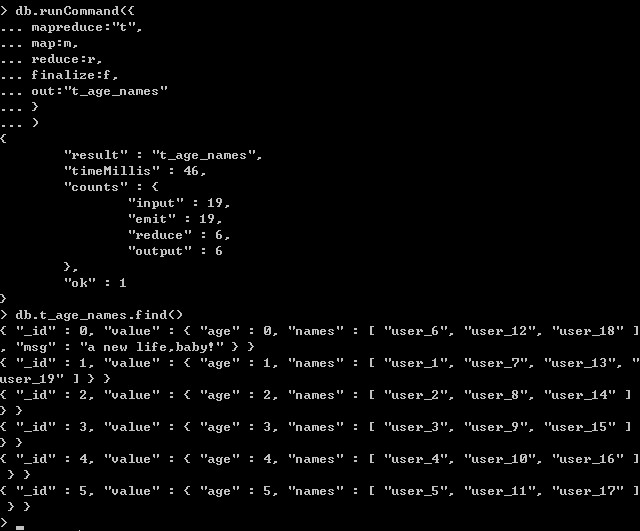
执行:
db.runCommand({
mapreduce:"t",//集合名字
map:m,
reduce:r,
finalize:f,
out:"t_age_names"
}
)

已有 0 条评论